Transit Database (Airtable)#
The Cal-ITP Airtable Transit Database stores key relationships about how transit services are organized and operated in California as well as how well they are performing. See Evan or post in the #data-airtable Slack channel to get a link and gain access.
Important Airtable documentation is maintained elsewhere:
Airtable Data Documentation Google Doc - documentation of specific fields in Airtable
California Transit Data - Operating Procedures Google Doc - outlines the processes by which Airtable data is maintained
In addition, some documentation is available automatically within Airtable (these require Airtable authentication to access):
Airtable creates an API documentation page for each base (for example, here is the page for California Transit). This page provides technical information about field types and relationships. Airtable does not currently have an effective mechanism to programmatically download your data schema (they have paused issuing keys to their metadata API).
When looking at a base, there is an
Extensionstab at the far upper right corner (below the share, notifications, and user icons). If you click that, an extensions sidebar will open. In that sidebar, there is an extension calledBase schema(you may have to open it fullscreen to actually see it.) This extension will let you see an auto-generated visualization of the technical relationships among fields in the base.
Cal-ITP uses two main Airtable bases:
Base |
Description |
|---|---|
Defines key organizational relationships and properties. Organizations, geography, funding programs, transit services, service characteristics, transit datasets such as GTFS, and the intersection between transit datasets and services. |
|
Defines operational setups at transit provider organizations. Defines relationships between vendor organizations, transit provider and operator organizations, products, contracts to provide products, transit stack components, and how they relate to one-another. |
The rest of this page outlines stray technical considerations associated with Airtable and its ingestion into the data warehouse.
Primary Keys#
Airtable forces the use of the left-most field as the primary key of the database: the field that must be referenced in other tables, similar to a VLOOKUP in a spreadsheet. Unlike many databases, Airtable doesn’t enforce uniqueness in the values of the primary key field. Instead, it assigns it an underlying and mostly hidden unique RECORD ID, which can be exposed by creating a formula field to reference it.
Importing Airtable data into the Cal-ITP data warehouse#
We ingest data from Airtable into the Cal-ITP data warehouse. For an overview of the data ingest process/architecture, see the pipeline architecture documentation. For pointers to where Airtable-specific code and artifacts, see the pipeline reference Google Sheet.
To ingest a new Airtable table or base and make it available in the warehouse, you need to make updates throughout the data ingest flow, from the Airtable scraper Airflow DAG all the way to dbt mart tables. See data infra PR #2781 for an example of what this can look like. Ingesting new columns in an existing table is similar; see data infra PR #2383 for an example.
Gotchas#
Bringing Airtable data into the warehouse can involve a few tricky situations. Here are a few we’ve encountered so far, with suggested resolutions.
Foreign keys and bridge tables#
Airtable allows users to define links between tables, to create relationships between records of different types. In the Airtable UI, these links display the primary field for the linked record in the relevant column (so, for example, the Services.provider column contains an organization’s name like City of Anaheim.) However, these foreign key links are exported via the Airtable API as an array of the back-end record IDs (so, instead of a single organization name like City of Anaheim, that Services.provider field will appear as an array containing a record ID, like [rec0123asdf].) It does this even if the given field only ever contains exactly one foreign key (i.e., it turns it into an array even if all the arrays have only one entry.)
This means:
All foreign keys need to be unpacked from arrays in the warehouse to become useful for joins. See below for more on this.
If a linked field is severed in Airtable (if the foreign key relationship is removed, but the columns that contained the links are not deleted) it can break our data ingest, because these array-type fields will become string-type fields. Ideally, it is best to just delete any associated columns when a foreign key relationship/link is ended. If this is not done and the data ingest does break, the solution is to suppress the broken column from the associated table by removing it from the external table schema. If the external table uses schema auto-detect, you may have to define a schema for the table that does not include the broken column. See data infra PR #2441 for an example of this process (though addressing a different issue.)
Airtable foreign keys in the warehouse also require some special handling because:
Most Airtable data is treated as dimensions (i.e., entities that we version over time)
Some Airtable data contains many-to-many relationships
The mechanism that we have used to deal with both of these is the bridge table, described in our dbt docs. The bridge table stores the foreign key pairs to allow you to traverse a relationship, instead of trying to store these on each of the tables in the relationship itself. Trying to store the foreign keys on the tables directly opens you up to issues:
You have to either store the foreign keys as an array or change the cardinality of the table (to account for the fact that one record may need to store multiple foreign keys, either to capture versioning on the foreign table or to capture relationships with multiple records). Metabase does not natively allow unnesting arrays to do joins in the GUI query editor, so we try to have non-array foreign keys in mart tables.
You risk infinite loops if you try to version a record that includes a versioned foreign key on both sides of the relationship (which is how Airtable stores these relationships). For example, you have an organization and a service that are linked, with both containing a foreign key to the other. An attribute is changed on the service, creating a new versioned key. You need to add that new versioned service key to the organization record. But now that has triggered a change on the organization record, which makes a new versioned key on the organization record. So now you have to update the organization versioned key on the service record. And thus to infinity. Another solution here is to only store the relationship on one side, but then you still have the first problem of arrays and cardinality.
Bridge tables do introduce some complexity in handling fanout from joins, but they remove that complexity from the dimension tables themselves. Another solution would be to only store the unversioned natural key for the foreign key, in which case you would only need bridge tables for true many-to-many relationships (to handle the array/cardinality issue), but that would still create fanout without the explicit artifact of the bridge table to help troubleshoot.
Synced tables#
Airtable allows you to “sync” a table from one base to another, where it appears with all the data from its source location and can be linked to records in the second base. An example in our Airtable is the California Transit.organizations table is synced to Transit Technology Stacks.organizations; you will see a little lightning icon to show that it is a synced table.
This requires special handling when importing to the warehouse, because Airtable assigns new back-end record IDs in the synced table, which means that foreign keys to the synced table in the second base will not match record IDs in the source table. We resolve this by mapping all foreign keys to point to the source table in a base layer in dbt. See data infra PR #2781 for an example.
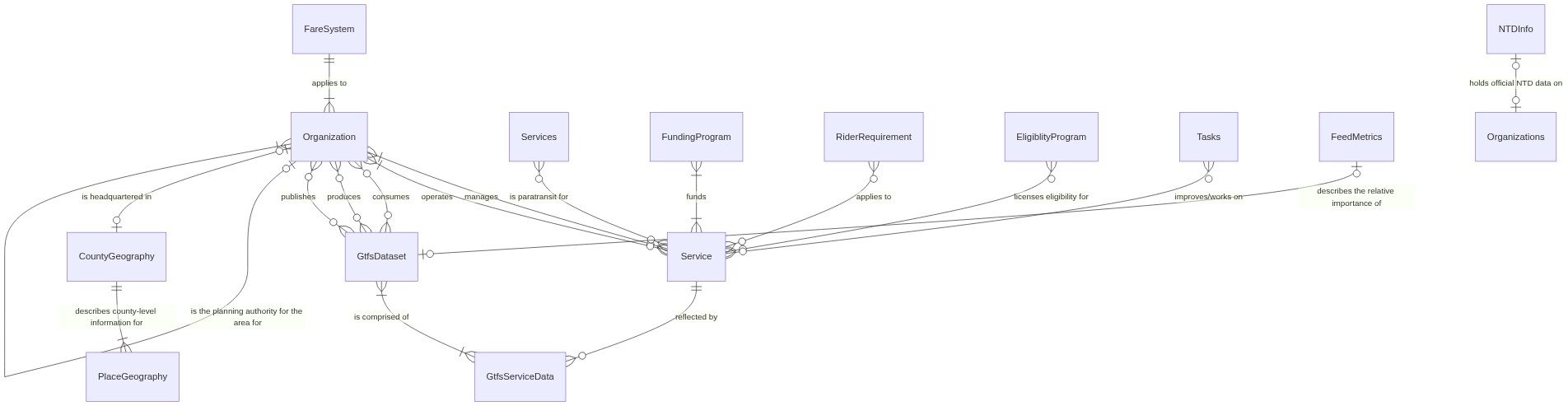
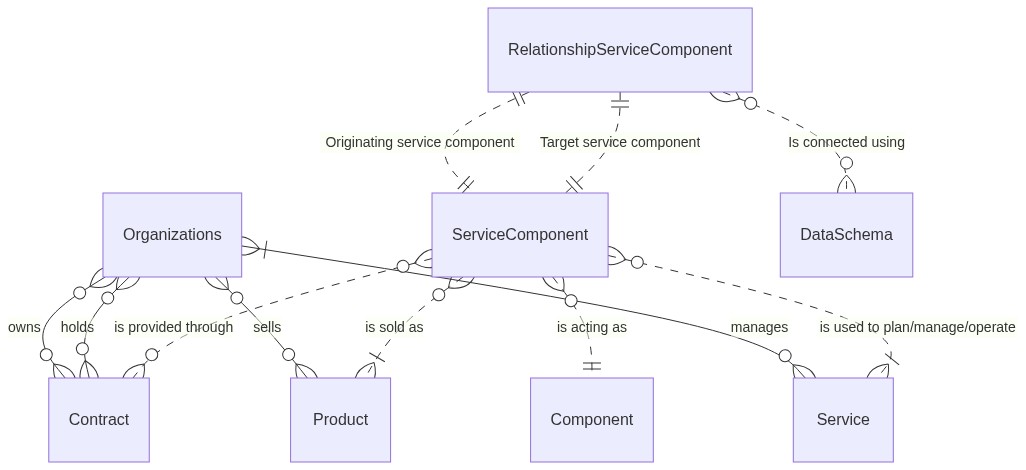
Entity Relationship Diagrams#
The following entity relationship diagrams were last updated in 2022 but are preserved for general reference purposes.
California Transit#
Transit Stacks#
DAGs Maintenance#
You can find further information on how to maintain the DAGs for Transit Database data on this page, which covers general Airflow maintenance and troubleshooting patterns.